12.2. Computação Assíncrona¶ Open the notebook in SageMaker Studio Lab
Os computadores de hoje são sistemas altamente paralelos, consistindo em vários núcleos de CPU (geralmente várias threads por núcleo), vários elementos de processamento por GPU e, muitas vezes, várias GPUs por dispositivo. Resumindo, podemos processar muitas coisas diferentes ao mesmo tempo, geralmente em dispositivos diferentes. Infelizmente, Python não é uma ótima maneira de escrever código paralelo e assíncrono, pelo menos não com alguma ajuda extra. Afinal, o Python é de thread único e é improvável que isso mude no futuro. Estruturas de aprendizado profundo, como MXNet e TensorFlow, utilizam um modelo de programação assíncrona para melhorar o desempenho (o PyTorch usa o próprio programador do Python, levando a uma compensação de desempenho diferente). Para PyTorch, por padrão, as operações de GPU são assíncronas. Quando você chama uma função que usa a GPU, as operações são enfileiradas no dispositivo específico, mas não necessariamente executadas até mais tarde. Isso nos permite executar mais cálculos em paralelo, incluindo operações na CPU ou outras GPUs.
Portanto, entender como a programação assíncrona funciona nos ajuda a desenvolver programas mais eficientes, reduzindo proativamente os requisitos computacionais e as dependências mútuas. Isso nos permite reduzir a sobrecarga de memória e aumentar a utilização do processador. Começamos importando as bibliotecas necessárias.
import os
import subprocess
import numpy
from mxnet import autograd, gluon, np, npx
from mxnet.gluon import nn
from d2l import mxnet as d2l
npx.set_np()
import os
import subprocess
import numpy
import torch
from torch import nn
from d2l import torch as d2l
12.2.1. Assincronismo via Back-end¶
Para um aquecimento, considere o seguinte problema brinquedo - queremos gerar uma matriz aleatória e multiplicá-la. Vamos fazer isso no NumPy e no MXNet NP para ver a diferença.
Para um aquecimento, considere o seguinte problema brinquedo - queremos
gerar uma matriz aleatória e multiplicá-la. Vamos fazer isso tanto no
NumPy quanto no tensor PyTorch para ver a diferença. Observe que o
tensor do PyTorch é definido em uma gpu.
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('mxnet.np'):
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
numpy: 0.9818 sec
mxnet.np: 0.0048 sec
Isso é ordens de magnitude mais rápido. Pelo menos parece que sim. Uma vez que ambos são executados no mesmo processador, algo mais deve estar acontecendo. Forçar o MXNet a terminar toda a computação antes de retornar mostra o que aconteceu anteriormente: a computação está sendo executada pelo back-end enquanto o front-end retorna o controle ao Python.
with d2l.Benchmark():
for _ in range(10):
a = np.random.normal(size=(1000, 1000))
b = np.dot(a, a)
npx.waitall()
Done: 0.9211 sec
De um modo geral, o MXNet possui um front-end para interação direta com
os usuários, por exemplo, via Python, bem como um back-end usado pelo
sistema para realizar a computação. Conforme mostrado em: numref:
fig_frontends, os usuários podem escrever programas MXNet em várias
linguagens de front-end, como Python, R, Scala e C ++. Independentemente
da linguagem de programação de front-end usada, a execução de programas
MXNet ocorre principalmente no back-end de implementações C ++. As
operações emitidas pela linguagem do front-end são passadas para o
back-end para execução. O back-end gerencia seus próprios threads que
continuamente coletam e executam tarefas enfileiradas. Observe que, para
que isso funcione, o back-end deve ser capaz de controlar as
dependências entre as várias etapas do gráfico computacional. Portanto,
não é possível paralelizar operações que dependem umas das outras.
# warmup for gpu computation
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
numpy: 0.8409 sec
torch: 0.0011 sec
Isso é ordens de magnitude mais rápido. Pelo menos parece que sim. O produto de ponto Numpy é executado no processador cpu enquanto A multiplicação da matriz de Pytorch é executada no gpu e, portanto, o último espera-se que seja muito mais rápida. Mas a enorme diferença de tempo sugere que algo mais deve estar acontecendo. Por padrão, as operações da GPU são assíncronas no PyTorch. Forçando PyTorch a terminar todos os cálculos antes de retornar os programas, o que aconteceu anteriormente: o cálculo está sendo executado pelo backend enquanto o front-end retorna o controle para Python.
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
Done: 0.0023 sec
Em termos gerais, o PyTorch tem um front-end para interação direta com
os usuários, por exemplo, via Python, bem como um back-end usado pelo
sistema para realizar a computação. Conforme mostrado em: numref:
fig_frontends, os usuários podem escrever programas PyTorch em
várias linguagens de front-end, como Python e C ++. Independentemente
da linguagem de programação de frontend usada, a execução de programas
PyTorch ocorre principalmente no backend de implementações C ++. As
operações emitidas pela linguagem do front-end são passadas para o
back-end para execução. O back-end gerencia suas próprias threads
que continuamente coletam e executam tarefas enfileiradas. Observe que
para que isso funcione, o back-end deve ser capaz de rastrear as
dependências entre várias etapas no gráfico computacional. Portanto, não
é possível paralelizar operações que dependem umas das outras.
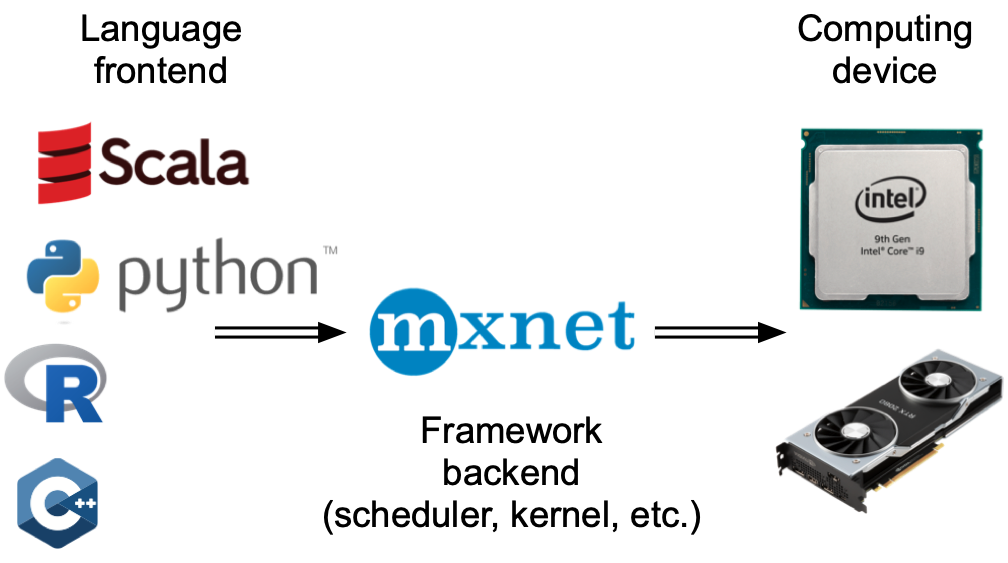
Fig. 12.2.1 Programação Frontend.¶
Vejamos outro exemplo brinquedo para entender um pouco melhor o grafo de dependência.
x = np.ones((1, 2))
y = np.ones((1, 2))
z = x * y + 2
z
array([[3., 3.]])
x = torch.ones((1, 2), device=device)
y = torch.ones((1, 2), device=device)
z = x * y + 2
z
tensor([[3., 3.]], device='cuda:0')

Fig. 12.2.2 Dependências.¶
O trecho de código acima também é ilustrado em
Fig. 12.2.2. Sempre que a thread de front-end do
Python executa uma das três primeiras instruções, ela simplesmente
retorna a tarefa para a fila de back-end. Quando os resultados da
última instrução precisam ser impressos, a thread de front-end do
Python irá esperar que athread de back-end do C ++ termine de
calcular o resultado da variável z. Um benefício desse design é
que a thread de front-end do Python não precisa realizar cálculos
reais. Portanto, há pouco impacto no desempenho geral do programa,
independentemente do desempenho do Python. Fig. 12.2.3
ilustra como front-end e back-end interagem.

Fig. 12.2.3 Frontend and Backend.¶
12.2.2. Barreiras e Bloqueadores¶
Existem várias operações que forçam o Python a aguardar a conclusão: *
Obviamente, npx.waitall () espera até que todo o cálculo seja
concluído, independentemente de quando as instruções de cálculo foram
emitidas. Na prática, é uma má ideia usar este operador, a menos que
seja absolutamente necessário, pois pode levar a um desempenho
insatisfatório. * Se quisermos apenas esperar até que uma variável
específica esteja disponível, podemos chamar z.wait_to_read ().
Nesse caso, os blocos MXNet retornam ao Python até que a variável z
seja calculada. Outros cálculos podem continuar depois.
Vamos ver como isso funciona na prática:
with d2l.Benchmark('waitall'):
b = np.dot(a, a)
npx.waitall()
with d2l.Benchmark('wait_to_read'):
b = np.dot(a, a)
b.wait_to_read()
waitall: 0.0366 sec
wait_to_read: 0.0066 sec
Ambas as operações levam aproximadamente o mesmo tempo para serem
concluídas. Além das operações de bloqueio óbvias, recomendamos que o
leitor esteja ciente dos bloqueadores implícitos. Imprimir uma
variável requer claramente que a variável esteja disponível e, portanto,
é um bloqueador. Por último, as conversões para NumPy via
z.asnumpy () e conversões para escalares via z.item () estão
bloqueando, uma vez que NumPy não tem noção de assincronismo. Ele
precisa acessar os valores assim como a função print. Copiar
pequenas quantidades de dados frequentemente do escopo do MXNet para
NumPy e vice-versa pode destruir o desempenho de um código eficiente,
uma vez que cada operação requer o gráfico computacional para avaliar
todos os resultados intermediários necessários para obter o termo
relevante antes que qualquer outra coisa possa ser feita.
with d2l.Benchmark('numpy conversion'):
b = np.dot(a, a)
b.asnumpy()
with d2l.Benchmark('scalar conversion'):
b = np.dot(a, a)
b.sum().item()
numpy conversion: 0.0216 sec
scalar conversion: 0.0323 sec
12.2.3. Melhorando a Computação¶
Em um sistema altamente multithread (mesmo laptops regulares têm 4
threads ou mais e em servidores multithread esse número pode exceder
256), a sobrecarga das operações de agendamento pode se tornar
significativa. É por isso que é altamente desejável que a computação e a
programação ocorram de forma assíncrona e em paralelo. Para ilustrar o
benefício de fazer isso, vamos ver o que acontece se incrementarmos uma
variável em 1 várias vezes, tanto em sequência quanto de forma
assíncrona. Simulamos a execução síncrona inserindo uma barreira
wait_to_read () entre cada adição.
with d2l.Benchmark('synchronous'):
for _ in range(1000):
y = x + 1
y.wait_to_read()
with d2l.Benchmark('asynchronous'):
for _ in range(1000):
y = x + 1
y.wait_to_read()
synchronous: 0.1225 sec
asynchronous: 0.0829 sec
Uma interação ligeiramente simplificada entre a thread de front-end Python e a thread de back-end C ++ pode ser resumida da seguinte maneira:
O front-end ordena que o back-end insira a tarefa de cálculo
y = x + 1na fila.O back-end então recebe as tarefas de computação da fila e executa os cálculos reais.
O back-end então retorna os resultados do cálculo para o front-end.
Suponha que as durações desses três estágios sejam \(t_1, t_2\) e \(t_3\), respectivamente. Se não usarmos a programação assíncrona, o tempo total necessário para realizar 1000 cálculos é de aproximadamente \(1000 (t_1+ t_2 + t_3)\). Se a programação assíncrona for usada, o tempo total gasto para realizar 1000 cálculos pode ser reduzido para \(t_1 + 1000 t_2 + t_3\) (assumindo \(1000 t_2> 999 t_1\)), uma vez que o front-end não precisa esperar que o back-end- retorne os resultados dos cálculos para cadaloop*.
12.2.4. Melhorando o Footprint de Memória¶
Imagine uma situação em que continuamos inserindo operações no
back-end, executando o código Python no front-end. Por exemplo, o
front-end pode inserir um grande número de tarefas de minibatch em um
tempo muito curto. Afinal, se nenhum cálculo significativo acontecer no
Python, isso pode ser feito rapidamente. Se cada uma dessas tarefas
puder ser iniciada rapidamente ao mesmo tempo, isso pode causar um
aumento no uso de memória. Dada uma quantidade finita de memória
disponível nas GPUs (e mesmo nas CPUs), isso pode levar à contenção de
recursos ou até mesmo travamentos do programa. Alguns leitores devem ter
notado que as rotinas de treinamento anteriores faziam uso de métodos de
sincronização como item ou mesmo asnumpy.
Recomendamos usar essas operações com cuidado, por exemplo, para cada minibatch, para equilibrar a eficiência computacional e a pegada de memória. Para ilustrar o que acontece, vamos implementar um loop de treinamento simples para uma rede profunda e medir seu consumo de memória e tempo. Abaixo está o gerador de dados simulado e a rede profunda.
def data_iter():
timer = d2l.Timer()
num_batches, batch_size = 150, 1024
for i in range(num_batches):
X = np.random.normal(size=(batch_size, 512))
y = np.ones((batch_size,))
yield X, y
if (i + 1) % 50 == 0:
print(f'batch {i + 1}, time {timer.stop():.4f} sec')
net = nn.Sequential()
net.add(nn.Dense(2048, activation='relu'),
nn.Dense(512, activation='relu'), nn.Dense(1))
net.initialize()
trainer = gluon.Trainer(net.collect_params(), 'sgd')
loss = gluon.loss.L2Loss()
Em seguida, precisamos de uma ferramenta para medir a pegada de memória
de nosso código. Usamos uma chamada ps relativamente primitiva para
fazer isso (observe que a última só funciona no Linux e MacOS). Para uma
análise muito mais detalhada do que está acontecendo aqui, use, por
exemplo, o
Nsight da
Nvidia ou o vTune da Intel.
def get_mem():
res = subprocess.check_output(['ps', 'u', '-p', str(os.getpid())])
return int(str(res).split()[15]) / 1e3
Antes de começarmos o teste, precisamos inicializar os parâmetros da rede e processar um lote. Caso contrário, seria complicado ver qual é o consumo de memória adicional. Veja Section 5.3 para mais detalhes relacionados à inicialização.
for X, y in data_iter():
break
loss(y, net(X)).wait_to_read()
Para garantir que não estouremos o buffer de tarefa no back-end,
inserimos uma chamada wait_to_read para a função de perda no final
de cada loop. Isso força a propagação direta a ser concluída antes que
uma nova propagação direta seja iniciada. Observe que uma alternativa
(possivelmente mais elegante) seria rastrear a perda em uma variável
escalar e forçar uma barreira por meio da chamada de item.
mem = get_mem()
with d2l.Benchmark('time per epoch'):
for X, y in data_iter():
with autograd.record():
l = loss(y, net(X))
l.backward()
trainer.step(X.shape[0])
l.wait_to_read() # Barrier before a new batch
npx.waitall()
print(f'increased memory: {get_mem() - mem:f} MB')
[04:02:35] src/base.cc:49: GPU context requested, but no GPUs found.
batch 50, time 4.2066 sec
batch 100, time 8.2570 sec
batch 150, time 12.1179 sec
time per epoch: 12.1193 sec
increased memory: 9.424000 MB
Como vemos, o tempo dos minibatches se alinha muito bem com o tempo de execução geral do código de otimização. Além disso, o consumo de memória aumenta apenas ligeiramente. Agora vamos ver o que acontece se derrubarmos a barreira no final de cada minibatch.
mem = get_mem()
with d2l.Benchmark('time per epoch'):
for X, y in data_iter():
with autograd.record():
l = loss(y, net(X))
l.backward()
trainer.step(X.shape[0])
npx.waitall()
print(f'increased memory: {get_mem() - mem:f} MB')
batch 50, time 0.1447 sec
batch 100, time 0.2817 sec
batch 150, time 0.3972 sec
time per epoch: 12.0468 sec
increased memory: 6.156000 MB
Mesmo que o tempo para emitir instruções para o back-end seja uma ordem de magnitude menor, ainda precisamos realizar o cálculo. Consequentemente, uma grande quantidade de resultados intermediários não pode ser liberada e pode se acumular na memória. Embora isso não tenha causado nenhum problema no exemplo acima, pode muito bem ter resultado em situações de falta de memória quando não verificado em cenários do mundo real.
12.2.5. Resumo¶
MXNet desacopla o front-end Python de um back-end de execução. Isso permite a rápida inserção assíncrona de comandos no back-end e o paralelismo associado.
O assincronismo leva a uma interface bastante responsiva. No entanto, tenha cuidado para não sobrecarregar a fila de tarefas, pois isso pode levar ao consumo excessivo de memória.
Recomenda-se sincronizar para cada minibatch para manter o front-end e o back-end aproximadamente sincronizados.
Esteja ciente do fato de que as conversões do gerenciamento de memória do MXNet para Python forçarão o* back-end* a esperar até que a variável específica esteja pronta.
print,asnumpyeitemtêm este efeito. Isso pode ser desejável, mas o uso sem carro da sincronização pode prejudicar o desempenho.Os fornecedores de chips oferecem ferramentas sofisticadas de análise de desempenho para obter uma visão muito mais detalhada da eficiência do deep learning.
12.2.6. Exercícios¶
Mencionamos acima que o uso de computação assíncrona pode reduzir a quantidade total de tempo necessária para realizar \(1000\) computações para \(t_1 + 1000 t_2 + t_3\). Por que temos que assumir \(1000 t_2 > 999 t_1\) aqui?
Como você precisaria modificar o loop de treinamento se quisesse ter uma sobreposição de um minibatch cada? Ou seja, se você quiser garantir que o lote \(b_t\) termine antes que o lote \(b_{t+2}\) comece?
O que pode acontecer se quisermos executar código em CPUs e GPUs simultaneamente? Você ainda deve insistir em sincronizar após cada minibatch ter sido emitido?
Meça a diferença entre
waitallewait_to_read. Dica: execute uma série de instruções e sincronize para um resultado intermediário.