12.4. Hardware¶ Open the notebook in SageMaker Studio Lab
Construir sistemas com ótimo desempenho requer um bom entendimento dos algoritmos e modelos para capturar os aspectos estatísticos do problema. Ao mesmo tempo, também é indispensável ter pelo menos um mínimo de conhecimento do hardware subjacente. A seção atual não substitui um curso apropriado sobre design de hardware e sistemas. Em vez disso, pode servir como um ponto de partida para entender por que alguns algoritmos são mais eficientes do que outros e como obter um bom rendimento. Um bom design pode facilmente fazer uma diferença de ordem de magnitude e, por sua vez, pode fazer a diferença entre ser capaz de treinar uma rede (por exemplo, em uma semana) ou não (em 3 meses, perdendo o prazo) . Começaremos examinando os computadores. Em seguida, daremos zoom para observar com mais cuidado as CPUs e GPUs. Por último, diminuímos o zoom para revisar como vários computadores estão conectados em um centro de servidores ou na nuvem. Este não é um guia de compra de GPU. Para isto, veja Section 19.5. Uma introdução à computação em nuvem com AWS pode ser encontrada em Section 19.3.
Leitores impacientes podem se virar com Fig. 12.4.1. Ele foi retirado da postagem interativa de Colin Scott , que oferece uma boa visão geral do progresso na última década. Os números originais são devidos à palestra de Stanford de 2010 de Jeff Dean. A discussão abaixo explica algumas das razões para esses números e como eles podem nos guiar no projeto de algoritmos. A discussão abaixo é de alto nível e superficial. Claramente, não substitui um curso adequado, mas apenas fornece informações suficientes para que um modelador estatístico tome decisões de projeto adequadas. Para uma visão geral aprofundada da arquitetura de computadores, recomendamos ao leitor [Hennessy & Patterson, 2011] ou um curso recente sobre o assunto, como o de Arste Asanovic.

Fig. 12.4.1 Números de latência que todo programador deve conhecer.¶
12.4.1. Computadores¶
A maioria dos pesquisadores de aprendizagem profunda tem acesso a um computador com uma boa quantidade de memória, computação, alguma forma de acelerador, como uma GPU, ou múltiplos deles. Consiste em vários componentes principais:
Um processador, também conhecido como CPU, que é capaz de executar os programas que fornecemos (além de executar um sistema operacional e muitas outras coisas), normalmente consistindo de 8 ou mais núcleos.
Memória (RAM) para armazenar e recuperar os resultados da computação, como vetores de peso, ativações, geralmente dados de treinamento.
Uma conexão de rede Ethernet (às vezes múltipla) com velocidades que variam de 1 Gbit / s a 100 Gbit / s (em servidores de ponta podem ser encontradas interconexões mais avançadas).
Um barramento de expansão de alta velocidade (PCIe) para conectar o sistema a uma ou mais GPUs. Os servidores têm até 8 aceleradores, geralmente conectados em uma topologia avançada, os sistemas desktop têm 1-2, dependendo do orçamento do usuário e do tamanho da fonte de alimentação.
O armazenamento durável, como um disco rígido magnético (HDD), estado sólido (SSD), em muitos casos conectado usando o barramento PCIe, fornece transferência eficiente de dados de treinamento para o sistema e armazenamento de pontos de verificação intermediários conforme necessário.

Fig. 12.4.2 Conectividade de componentes¶
Como Fig. 12.4.2 indica, a maioria dos componentes (rede, GPU, armazenamento) são conectados à CPU através do barramento PCI Express. Ele consiste em várias pistas diretamente conectadas à CPU. Por exemplo, o Threadripper 3 da AMD tem 64 pistas PCIe 4.0, cada uma das quais é capaz de transferência de dados de 16 Gbit/s em ambas as direções. A memória é conectada diretamente à CPU com uma largura de banda total de até 100 GB/s.
Quando executamos o código em um computador, precisamos embaralhar os dados para os processadores (CPU ou GPU), realizarem cálculos e, em seguida, mover os resultados do processador de volta para a RAM e armazenamento durável. Portanto, para obter um bom desempenho, precisamos nos certificar de que isso funcione perfeitamente, sem que nenhum dos sistemas se torne um grande gargalo. Por exemplo, se não conseguirmos carregar as imagens com rapidez suficiente, o processador não terá nenhum trabalho a fazer. Da mesma forma, se não conseguirmos mover as matrizes com rapidez suficiente para a CPU (ou GPU), seus elementos de processamento morrerão de fome. Finalmente, se quisermos sincronizar vários computadores na rede, o último não deve retardar a computação. Uma opção é intercalar comunicação e computação. Vamos dar uma olhada nos vários componentes com mais detalhes.
12.4.2. Memória¶
Em sua forma mais básica, a memória é usada para armazenar dados que precisam estar prontamente acessíveis. Atualmente, a CPU RAM é tipicamente da variedade DDR4, oferecendo largura de banda de 20-25GB/s por módulo. Cada módulo possui um barramento de 64 bits. Normalmente, pares de módulos de memória são usados para permitir vários canais. As CPUs têm entre 2 e 4 canais de memória, ou seja, têm entre 40 GB/s e 100 GB/s de largura de banda de memória de pico. Freqüentemente, existem dois bancos por canal. Por exemplo, o Zen 3 Threadripper da AMD tem 8 slots.
Embora esses números sejam impressionantes, na verdade, eles contam apenas parte da história. Quando queremos ler uma parte da memória, primeiro precisamos dizer ao módulo de memória onde a informação pode ser encontrada. Ou seja, primeiro precisamos enviar o endereço para a RAM. Feito isso, podemos escolher ler apenas um único registro de 64 bits ou uma longa sequência de registros. Este último é chamado de leitura intermitente. Resumindo, enviar um endereço para a memória e configurar a transferência leva aproximadamente 100 ns (os detalhes dependem dos coeficientes de tempo específicos dos chips de memória usados), cada transferência subsequente leva apenas 0,2 ns. Resumindo, a primeira leitura é 500 vezes mais cara que as subsequentes! Poderíamos realizar até \(10.000.000\) leituras aleatórias por segundo. Isso sugere que evitamos o acesso aleatório à memória o máximo possível e, em vez disso, usamos leituras (e gravações) intermitentes.
As coisas ficam um pouco mais complexas quando levamos em consideração que temos vários bancos. Cada banco pode ler a memória independentemente. Isso significa duas coisas: o número efetivo de leituras aleatórias é até 4x maior, desde que sejam distribuídas uniformemente pela memória. Isso também significa que ainda é uma má ideia realizar leituras aleatórias, uma vez que as leituras intermitentes também são 4x mais rápidas. Em segundo lugar, devido ao alinhamento da memória aos limites de 64 bits, é uma boa ideia alinhar quaisquer estruturas de dados com os mesmos limites. Compiladores fazem isso automaticamente quando os sinalizadores apropriados são definidos. Os leitores curiosos são incentivados a revisar uma palestra sobre DRAMs, como a de Zeshan Chishti.
A memória da GPU está sujeita a requisitos de largura de banda ainda maiores, uma vez que têm muito mais elementos de processamento do que CPUs. Em geral, existem duas opções para resolvê-los. Uma é tornar o barramento de memória significativamente mais amplo. Por exemplo, o RTX 2080 Ti da NVIDIA tem um barramento de 352 bits. Isso permite que muito mais informações sejam transferidas ao mesmo tempo. Em segundo lugar, as GPUs usam memória específica de alto desempenho. Dispositivos de consumo, como as séries RTX e Titan da NVIDIA, geralmente usam chips GDDR6 com largura de banda agregada superior a 500 GB / s. Uma alternativa é usar módulos HBM (memória de alta largura de banda). Eles usam uma interface muito diferente e se conectam diretamente com GPUs em um wafer de silício dedicado. Isso os torna muito caros e seu uso é normalmente limitado a chips de servidor de ponta, como a série de aceleradores NVIDIA Volta V100. Sem surpresa, a memória da GPU é muito menor do que a memória da CPU devido ao seu custo mais alto. Para nossos propósitos, em geral, suas características de desempenho são semelhantes, apenas muito mais rápidas. Podemos ignorar com segurança os detalhes para o propósito deste livro. Eles só importam ao ajustar os kernels da GPU para alto rendimento.
12.4.3. Armazenamento¶
Vimos que algumas das principais características da RAM eram largura de banda e latência. O mesmo é verdade para dispositivos de armazenamento, só que as diferenças podem ser ainda mais extremas.
Discos rígidos são usados há mais de meio século. Em poucas palavras, eles contêm uma série de pratos giratórios com cabeças que podem ser posicionadas para ler / escrever em qualquer faixa. Discos de última geração suportam até 16 TB em 9 pratos. Um dos principais benefícios dos HDDs é que eles são relativamente baratos. Uma de suas muitas desvantagens são seus modos de falha tipicamente catastróficos e sua latência de leitura relativamente alta.
Para entender o último, considere o fato de que os HDDs giram em torno de 7.200 RPM. Se fossem muito mais rápidos, estilhaçariam devido à força centrífuga exercida nas travessas. Isso tem uma grande desvantagem quando se trata de acessar um setor específico no disco: precisamos esperar até que o prato tenha girado na posição (podemos mover as cabeças, mas não acelerar os discos reais). Portanto, pode demorar mais de 8 ms até que os dados solicitados estejam disponíveis. Uma maneira comum de expressar isso é dizer que os HDDs podem operar a aproximadamente 100 IOPs. Este número permaneceu essencialmente inalterado nas últimas duas décadas. Pior ainda, é igualmente difícil aumentar a largura de banda (é da ordem de 100-200 MB/s). Afinal, cada cabeçote lê uma trilha de bits, portanto, a taxa de bits é dimensionada apenas com a raiz quadrada da densidade da informação. Como resultado, os HDDs estão rapidamente se tornando relegados ao armazenamento de arquivos e armazenamento de baixo nível para conjuntos de dados muito grandes.
Unidades de estado sólido usam memória Flash para armazenar informações de forma persistente. Isso permite um acesso muito mais rápido aos registros armazenados. Os SSDs modernos podem operar de 100.000 a 500.000 IOPs, ou seja, até 3 ordens de magnitude mais rápido do que os HDDs. Além disso, sua largura de banda pode chegar a 1-3 GB/s, ou seja, uma ordem de magnitude mais rápida do que os HDDs. Essas melhorias parecem boas demais para ser verdade. Na verdade, eles vêm com uma série de ressalvas, devido à forma como os SSDs são projetados.
SSDs armazenam informações em blocos (256 KB ou maiores). Eles só podem ser escritos como um todo, o que leva um tempo significativo. Consequentemente, as gravações aleatórias bit a bit no SSD têm um desempenho muito ruim. Da mesma forma, a gravação de dados em geral leva um tempo significativo, pois o bloco deve ser lido, apagado e então reescrito com novas informações. Até agora, os controladores SSD e firmware desenvolveram algoritmos para atenuar isso. No entanto, as gravações podem ser muito mais lentas, em particular para SSDs QLC (célula de nível quádruplo). A chave para um melhor desempenho é manter uma fila de operações, preferir leituras e escrever em grandes blocos, se possível.
As células de memória em SSDs se desgastam com relativa rapidez (geralmente após alguns milhares de gravações). Algoritmos de proteção de nível de desgaste são capazes de espalhar a degradação por muitas células. Dito isso, não é recomendado usar SSDs para arquivos de troca ou para grandes agregações de arquivos de log.
Por último, o grande aumento na largura de banda forçou os designers de computador a conectar SSDs diretamente ao barramento PCIe. As unidades capazes de lidar com isso, chamadas de NVMe (Non Volatile Memory Enhanced), podem usar até 4 pistas PCIe. Isso equivale a até 8 GB / s no PCIe 4.0.
Cloud Storage oferece uma gama configurável de desempenho. Ou seja, a atribuição de armazenamento às máquinas virtuais é dinâmica, tanto em termos de quantidade quanto em termos de velocidade, escolhidos pelo usuário. Recomendamos que o usuário aumente o número provisionado de IOPs sempre que a latência for muito alta, por exemplo, durante o treinamento com muitos registros pequenos.
12.4.4. CPUs¶
As Unidades de Processamento Central (CPUs) são a peça central de qualquer computador (como antes, damos uma descrição de alto nível focando principalmente no que importa para modelos de aprendizado profundo eficientes). Eles consistem em uma série de componentes principais: núcleos de processador que são capazes de executar código de máquina, um barramento conectando-os (a topologia específica difere significativamente entre modelos de processador, gerações e fornecedores) e caches para permitir maior largura de banda e menor latência de acesso à memória do que o que é possível por leituras da memória principal. Por fim, quase todas as CPUs modernas contêm unidades de processamento vetorial para auxiliar na álgebra linear e convoluções de alto desempenho, pois são comuns no processamento de mídia e no aprendizado de máquina.

Fig. 12.4.3 CPU Intel Skylake para consumidor quad-core¶
Fig. 12.4.3 representa uma CPU quad-core Intel Skylake para o consumidor. Ele tem uma GPU integrada, caches e um ringbus conectando os quatro núcleos. Os periféricos (Ethernet, WiFi, Bluetooth, controlador SSD, USB, etc.) fazem parte do chipset ou são conectados diretamente (PCIe) à CPU.
12.4.4.1. Microarquitetura¶
Cada um dos núcleos do processador consiste em um conjunto bastante sofisticado de componentes. Embora os detalhes sejam diferentes entre gerações e fornecedores, a funcionalidade básica é praticamente padrão. O front-end carrega instruções e tenta prever qual caminho será seguido (por exemplo, para o fluxo de controle). As instruções são então decodificadas do código de montagem para as microinstruções. O código assembly geralmente não é o código de nível mais baixo que um processador executa. Em vez disso, instruções complexas podem ser decodificadas em um conjunto de operações de nível mais baixo. Em seguida, eles são processados pelo núcleo de execução real. Freqüentemente, o último é capaz de realizar várias operações simultaneamente. Por exemplo, o núcleo ARM Cortex A77 de Fig. 12.4.4 é capaz de realizar até 8 operações simultaneamente.

Fig. 12.4.4 Visão geral da microarquitetura ARM Cortex A77¶
Isso significa que programas eficientes podem ser capazes de executar mais de uma instrução por ciclo de clock, desde que possam ser executados independentemente. Nem todas as unidades são criadas iguais. Alguns se especializam em instruções de inteiros, enquanto outros são otimizados para desempenho de ponto flutuante. Para aumentar a taxa de transferência, o processador também pode seguir vários codepaths simultaneamente em uma instrução de ramificação e, em seguida, descartar os resultados das ramificações não realizadas. É por isso que as unidades de previsão de ramificação são importantes (no front-end) de forma que apenas os caminhos mais promissores são seguidos.
12.4.4.2. Vetorização¶
O aprendizado profundo exige muita computação. Portanto, para tornar as CPUs adequadas para aprendizado de máquina, é necessário realizar muitas operações em um ciclo de clock. Isso é obtido por meio de unidades vetoriais. Eles têm nomes diferentes: no ARM são chamados de NEON, no x86 a última geração é conhecida como unidades AVX2. Um aspecto comum é que eles são capazes de realizar operações SIMD (instrução única, dados múltiplos). Fig. 12.4.5 mostra como 8 inteiros curtos podem ser adicionados em um ciclo de clock no ARM.

Fig. 12.4.5 Vetorização NEON de 128 bits¶
Dependendo das opções de arquitetura, esses registros têm até 512 bits de comprimento, permitindo a combinação de até 64 pares de números. Por exemplo, podemos multiplicar dois números e adicioná-los a um terceiro, também conhecido como multiplicação-adição fundida. O OpenVino da Intel usa isso para atingir um rendimento respeitável para aprendizado profundo em CPUs de nível de servidor. Observe, porém, que esse número é totalmente diminuto em relação ao que as GPUs são capazes de alcançar. Por exemplo, o RTX 2080 Ti da NVIDIA tem 4.352 núcleos CUDA, cada um dos quais é capaz de processar tal operação a qualquer momento.
12.4.4.3. Cache¶
Considere a seguinte situação: temos um modesto núcleo de CPU com 4 núcleos, conforme ilustrado em Fig. 12.4.3 acima, rodando na frequência de 2 GHz. Além disso, vamos supor que temos uma contagem IPC (instruções por clock) de 1 e que as unidades têm AVX2 com largura de 256 bits habilitada. Além disso, vamos supor que pelo menos um dos registradores usados para as operações AVX2 precisa ser recuperado da memória. Isso significa que a CPU consome 4x256bit = 1kbit de dados por ciclo de clock. A menos que possamos transferir \(2 \cdot 10^9 \cdot 128 = 256 \cdot 10^9\) bytes para o processador por segundo, os elementos de processamento morrerão de fome. Infelizmente, a interface de memória de um tal chip suporta apenas transferência de dados de 20-40 GB/s, ou seja, uma ordem de magnitude a menos. A correção é evitar o carregamento de novos dados da memória o máximo possível e, em vez disso, armazená-los em cache localmente na CPU. É aqui que os caches são úteis (consulte este artigo da Wikipedia para uma introdução). Normalmente, os seguintes nomes / conceitos são usados:
Registradores, estritamente falando, não fazem parte do cache. Eles ajudam a preparar as instruções. Dito isso, os registradores da CPU são locais de memória que uma CPU pode acessar na velocidade do clock sem nenhuma penalidade de atraso. CPUs têm dezenas de registradores. Cabe ao compilador (ou programador) usar os registradores de maneira eficiente. Por exemplo, a linguagem de programação C tem uma palavra-chave
register.Os caches L1 são a primeira linha de defesa contra os altos requisitos de largura de banda da memória. Os caches L1 são minúsculos (os tamanhos típicos podem ser de 32-64kB) e geralmente se dividem em caches de dados e instruções. Quando os dados são encontrados no cache L1, o acesso é muito rápido. Se não puder ser encontrado lá, a pesquisa progride para baixo na hierarquia do cache.
Caches L2 são a próxima parada. Dependendo do design da arquitetura e do tamanho do processador, eles podem ser exclusivos. Eles podem ser acessíveis apenas por um determinado núcleo ou compartilhados entre vários núcleos. Os caches L2 são maiores (normalmente 256-512kB por núcleo) e mais lentos do que L1. Além disso, para acessar algo em L2, primeiro precisamos verificar para perceber que os dados não estão em L1, o que adiciona uma pequena quantidade de latência extra.
Caches L3 são compartilhados entre vários núcleos e podem ser muito grandes. As CPUs do servidor Epyc 3 da AMD têm 256 MB de cache espalhados por vários chips. Os números mais comuns estão na faixa de 4 a 8 MB.
Prever quais elementos de memória serão necessários em seguida é um dos principais parâmetros de otimização no projeto do chip. Por exemplo, é aconselhável percorrer a memória em uma direção para frente, pois a maioria dos algoritmos de cache tentará ler para a frente em vez de para trás. Da mesma forma, manter os padrões de acesso à memória locais é uma boa maneira de melhorar o desempenho. Adicionar caches é uma faca de dois gumes. Por um lado, eles garantem que os núcleos do processador não morram de fome de dados. Ao mesmo tempo, eles aumentam o tamanho do chip, consumindo área que, de outra forma, poderia ser gasta no aumento do poder de processamento. Além disso, falhas de cache podem ser caras. Considere o pior cenário, descrito em: Fig. 12.4.6. Um local de memória é armazenado em cache no processador 0 quando uma thread no processador 1 solicita os dados. Para obtê-lo, o processador 0 precisa parar o que está fazendo, gravar as informações de volta na memória principal e deixar que o processador 1 as leia da memória. Durante esta operação, os dois processadores aguardam. Muito potencialmente, esse código é executado mais lentamente em vários processadores quando comparado a uma implementação eficiente de processador único. Esse é mais um motivo pelo qual há um limite prático para o tamanho da cache (além do tamanho físico).

Fig. 12.4.6 Compartilhamento falso (imagem cortesia da Intel)¶
12.4.5. GPUs e outros Aceleradores¶
Não é exagero afirmar que o deep learning não teria tido sucesso sem as GPUs. Da mesma forma, é bastante razoável argumentar que as fortunas dos fabricantes de GPUs aumentaram significativamente devido ao deep learning. Essa coevolução de hardware e algoritmos levou a uma situação em que, para melhor ou pior, o deep learning é o paradigma de modelagem estatística preferível. Portanto, vale a pena entender os benefícios específicos que as GPUs e aceleradores relacionados, como a TPU [Jouppi et al., 2017] oferecem.
É digno de nota uma distinção que é frequentemente feita na prática: os aceleradores são otimizados para treinamento ou inferência. Para o último, só precisamos calcular a propagação direta em uma rede. Nenhum armazenamento de dados intermediários é necessário para retropropagação. Além disso, podemos não precisar de cálculos muito precisos (FP16 ou INT8 normalmente são suficientes). Por outro lado, durante o treinamento, todos os resultados intermediários precisam ser armazenados para calcular os gradientes. Além disso, o acúmulo de gradientes requer maior precisão para evitar underflow numérico (ou estouro). Isso significa que FP16 (ou precisão mista com FP32) é o mínimo necessário. Tudo isso requer memória maior e mais rápida (HBM2 vs. GDDR6) e mais poder de processamento. Por exemplo, as GPUs T4 da NVIDIA Turing são otimizadas para inferência, enquanto as GPUs V100 são preferíveis para treinamento.
Lembre-se de Fig. 12.4.5. Adicionar unidades de vetor a um núcleo de processador nos permitiu aumentar o rendimento significativamente (no exemplo da figura, fomos capazes de realizar 16 operações simultaneamente). E se adicionássemos operações que otimizassem não apenas as operações entre vetores, mas também entre matrizes? Essa estratégia levou ao Tensor Cores (mais sobre isso em breve). Em segundo lugar, e se adicionarmos muitos mais núcleos? Em suma, essas duas estratégias resumem as decisões de design em GPUs. Fig. 12.4.7 dá uma visão geral sobre um bloco de processamento básico. Ele contém 16 unidades inteiras e 16 unidades de ponto flutuante. Além disso, dois núcleos do Tensor aceleram um subconjunto estreito de operações adicionais relevantes para o aprendizado profundo. Cada Streaming Multiprocessor (SM) consiste em quatro desses blocos.
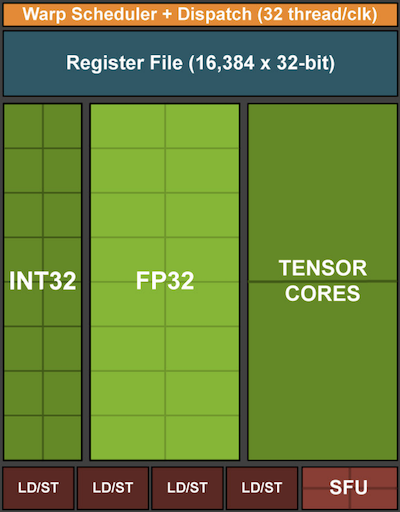
Fig. 12.4.7 Bloco de Processamento NVIDIA Turing (imagem cortesia da NVIDIA)¶
12 multiprocessadores de streaming são então agrupados em clusters de processamento gráfico que compõem os processadores TU102 de última geração. Canais de memória amplos e um cache L2 complementam a configuração. Fig. 12.4.8 tem os detalhes relevantes. Uma das razões para projetar tal dispositivo é que blocos individuais podem ser adicionados ou removidos conforme necessário para permitir chips mais compactos e lidar com problemas de rendimento (módulos defeituosos podem não ser ativados). Felizmente, a programação de tais dispositivos está bem escondida do pesquisador casual de aprendizado profundo sob camadas de CUDA e código de estrutura. Em particular, mais de um dos programas pode muito bem ser executado simultaneamente na GPU, desde que haja recursos disponíveis. No entanto, vale a pena estar ciente das limitações dos dispositivos para evitar escolher modelos que não cabem na memória do dispositivo.

Fig. 12.4.8 Arquitetura NVIDIA Turing (imagem cortesia da NVIDIA)¶
Um último aspecto que vale a pena mencionar com mais detalhes são os TensorCores. Eles são um exemplo de uma tendência recente de adicionar circuitos mais otimizados que são especificamente eficazes para o aprendizado profundo. Por exemplo, o TPU adicionou uma matriz sistólica [Kung, 1988]para multiplicação rápida da matriz. Lá, o projeto deveria suportar um número muito pequeno (um para a primeira geração de TPUs) de grandes operações. TensorCores estão na outra extremidade. Eles são otimizados para pequenas operações envolvendo matrizes entre 4x4 e 16x16, dependendo de sua precisão numérica. Fig. 12.4.9 dá uma visão geral das otimizações.
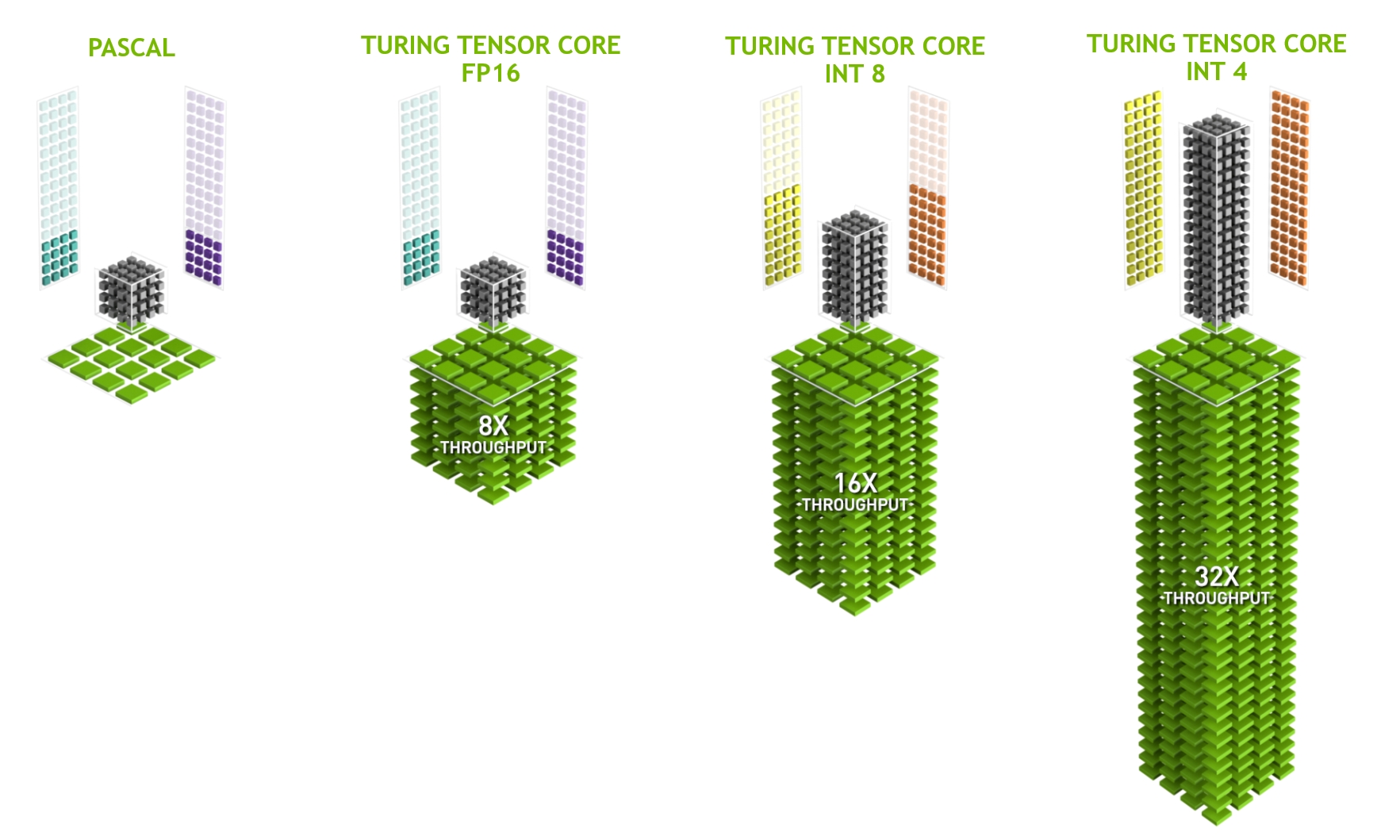
Fig. 12.4.9 NVIDIA TensorCores de Turing (imagem cortesia da NVIDIA)¶
Obviamente, ao otimizar para computação, acabamos fazendo certos compromissos. Um deles é que as GPUs não são muito boas em lidar com interrupções e dados esparsos. Embora haja exceções notáveis, como Gunrock [Wang et al., 2016], o padrão de acesso de matrizes e vetores esparsos não vai bem com as operações de leitura intermitente de alta largura de banda em que as GPUs se destacam. Combinar os dois objetivos é uma área de pesquisa ativa. Veja, por exemplo, DGL, uma biblioteca ajustada para deep learning em gráficos.
12.4.6. Redes e Barramentos¶
Sempre que um único dispositivo é insuficiente para a otimização, precisamos transferir dados de e para ele para sincronizar o processamento. É aqui que as redes e os barramentos são úteis. Temos vários parâmetros de design: largura de banda, custo, distância e flexibilidade. Por um lado, temos WiFi que tem um alcance muito bom, é muito fácil de usar (sem fios, afinal), barato, mas oferece largura de banda e latência comparativamente medíocres. Nenhum pesquisador de aprendizado de máquina em sã consciência o usaria para construir um cluster de servidores. A seguir, enfocamos as interconexões adequadas para o deep learning.
PCIe é um barramento dedicado para conexões ponto a ponto de largura de banda muito alta (até 16 Gbs em PCIe 4.0) por lane. A latência é da ordem de microssegundos de um dígito (5 μs). Os links PCIe são preciosos. Os processadores têm apenas um número limitado deles: o EPYC 3 da AMD tem 128 lanes, o Xeon da Intel tem até 48 lanes por chip; em CPUs para desktop os números são 20 (Ryzen 9) e 16 (Core i9), respectivamente. Como as GPUs têm normalmente 16 lanes, isso limita o número de GPUs que podem se conectar à CPU em largura de banda total. Afinal, elas precisam compartilhar os links com outros periféricos de alta largura de banda, como armazenamento e Ethernet. Assim como com o acesso à RAM, grandes transferências em massa são preferíveis devido à sobrecarga de pacotes reduzida.
Ethernet é a forma mais comumente usada de conectar computadores. Embora seja significativamente mais lento que o PCIe, é muito barato e resistente para instalar e cobre distâncias muito maiores. A largura de banda típica para servidores de baixo nível é de 1 GBit/s. Dispositivos de ponta (por exemplo, instâncias C5 na nuvem) oferecem entre 10 e 100 GBit/s de largura de banda. Como em todos os casos anteriores, a transmissão de dados tem sobrecargas significativas. Observe que quase nunca usamos Ethernet bruta diretamente, mas sim um protocolo executado na parte superior da interconexão física (como UDP ou TCP/IP). Isso adiciona mais sobrecarga. Como PCIe, Ethernet é projetada para conectar dois dispositivos, por exemplo, um computador e um switch.
Switches nos permitem conectar vários dispositivos de maneira que qualquer par deles possa realizar uma conexão ponto a ponto (normalmente largura de banda total) simultaneamente. Por exemplo, comutadores Ethernet podem conectar 40 servidores em alta largura de banda transversal. Observe que os switches não são exclusivos das redes de computadores tradicionais. Mesmo as pistas PCIe podem ser trocadas. Isso ocorre, por exemplo, para conectar um grande número de GPUs a um processador host, como é o caso das instâncias P2.
NVLink é uma alternativa ao PCIe quando se trata de interconexões de largura de banda muito alta. Ele oferece uma taxa de transferência de dados de até 300 Gbit/s por link. As GPUs de servidor (Volta V100) têm 6 links, enquanto as GPUs de consumidor (RTX 2080 Ti) têm apenas um link, operando a uma taxa reduzida de 100 Gbit/s. Recomendamos usar NCCL para obter alta transferência de dados entre GPUs.
12.4.7. Resumo¶
Dispositivos têm sobrecargas para operações. Portanto, é importante ter como objetivo um pequeno número de transferências grandes, em vez de muitas transferências pequenas. Isso se aplica a RAM, SSDs, redes e GPUs.
A vetorização é a chave para o desempenho. Certifique-se de estar ciente das habilidades específicas de seu acelerador. Por exemplo, algumas CPUs Intel Xeon são particularmente boas para operações INT8, GPUs NVIDIA Volta se destacam em operações matriz-matriz FP16 e NVIDIA Turing brilha em operações FP16, INT8 e INT4.
O estouro numérico devido a pequenos tipos de dados pode ser um problema durante o treinamento (e em menor extensão durante a inferência).
O aliasing pode degradar significativamente o desempenho. Por exemplo, o alinhamento da memória em CPUs de 64 bits deve ser feito em relação aos limites de 64 bits. Em GPUs, é uma boa ideia manter os tamanhos de convolução alinhados, por exemplo, para TensorCores.
Combine seus algoritmos com o hardware (pegada de memória, largura de banda, etc.). Grande aceleração (ordens de magnitude) podem ser alcançadas ao ajustar os parâmetros em caches.
Recomendamos que você esboce o desempenho de um novo algoritmo no papel antes de verificar os resultados experimentais. Discrepâncias de ordem de magnitude ou mais são motivos de preocupação.
Use profilers para depurar gargalos de desempenho.
O hardware de treinamento e inferência tem diferentes pontos ideais em termos de preço / desempenho.
12.4.8. Mais Números de Latência¶
O resumo em Table 12.4.1 e Table 12.4.2 são devidos a Eliot Eshelman que mantém uma versão atualizada dos números como um GitHub Gist.
Ação |
T e m p o |
Notas |
|---|---|---|
Referência / acerto do cache L1 |
5 n s |
4 ciclos |
Adicionar ponto flutuante / mult / FMA |
5 n s |
4 ciclos |
Referência / acerto do cache L2 |
5 n s |
12 ~ 17 ciclos |
Erro de previsão de branch |
6 n s |
15 ~ 20 ciclos |
Acerto de cache L3 (cache não compartilhado) |
1 6 n s |
42 ciclos |
Acerto de cache L3 (compartilhado em outro núcleo) |
2 5 n s |
65 ciclos |
Bloqueio / desbloqueio Mutex |
2 5 n s |
|
Acerto de cache L3 (modificado em outro núcleo) |
2 9 n s |
75 ciclos |
Acerto de cache L3 (em um soquete de CPU remoto) |
4 0 n s |
100 ~ 300 ciclos (40 ~ 116 ns) |
Salto QPI para outra CPU (por salto) |
4 0 n s |
|
Ref. de memória 64 MB (CPU local) |
4 6 n s |
TinyMemBench na Broadwell E5-2690v4 |
Ref. de memória 64 MB (CPU remota) |
7 0 n s |
TinyMemBench na Broadwell E5-2690v4 |
Ref. de memória 256 MB (CPU local) |
7 5 n s |
TinyMemBench na Broadwell E5-2690v4 |
Gravação aleatória Intel Optane |
9 4 n s |
UCSD Systems Lab Não-Volátil |
Ref. de memória 256 MB (CPU remota) |
1 2 0 n s |
TinyMemBench na Broadwell E5-2690v4 |
Leitura aleatória Intel Optane |
3 0 5 n s |
UCSD Systems Lab Não-Volátil |
Enviar 4KB em HPC fabric com mais de 100 Gbps |
1 μ s |
MVAPICH2 sobre Intel Omni-Path |
Comprimir 1 KB com Google Snappy |
3 μ s |
|
Enviar 4 KB por Ethernet de 10 Gbps |
1 0 μ s |
|
Gravar 4KB aleatoriamente no NVMe SSD |
3 0 μ s |
DC P3608 NVMe SSD (QOS 99% é 500μs) |
Transferir 1 MB de/para GPU NVLink |
3 0 μ s |
~33GB/s na NVIDIA 40GB NVLink |
Transferir 1 MB de/para GPU PCI-E |
8 0 μ s |
~12GB/s na PCIe 3.0 x16 link |
Ler 4 KB aleatoriamente do NVMe SSD |
1 2 0 μ s |
DC P3608 NVMe SSD (QOS 99%) |
Ler 1 MB sequencialmente do NVMe SSD |
2 0 8 μ s |
~4.8GB/s DC P3608 NVMe SSD |
Gravar 4 KB aleatoriamente em SATA SSD |
5 0 0 μ s |
DC S3510 SATA SSD (QOS 99.9%) |
Ler 4 KB aleatoriamente de SATA SSD |
5 0 0 μ s |
DC S3510 SATA SSD (QOS 99.9%) |
Ida e volta no mesmo datacenter |
5 0 0 μ s |
Ping one-way é ~250μs |
Ler 1 MB sequencialmente de SATA SSD |
2 m s |
~550MB/s DC S3510 SATA SSD |
Ler 1 MB sequencialmente do disco |
5 m s |
~200MB/s servidor HDD |
Acesso aleatório ao disco (busca + rotação) |
1 0 m s |
|
Enviar pacote Califórnia-> Holanda-> Califórnia |
1 5 0 m s |
Ação |
Te mp o |
Notas |
|---|---|---|
Acesso à memória compartilhada da GPU |
30 ns |
30~90 cycles (conflitos de banco adicionam latência) |
Acesso à memória global da GPU |
20 0 ns |
200~800 ciclos |
Iniciar o kernel CUDA na GPU |
10 μs |
A CPU do host instrui a GPU a iniciar o kernel |
Transferir 1 MB de / para GPU NVLink |
30 μs |
~33GB/s na NVIDIA 40GB NVLink |
Transferir 1 MB de / para GPU PCI-E |
80 μs |
~12GB/s na PCI-Express x16 link |
12.4.9. Exercícios¶
Escreva o código C para testar se há alguma diferença na velocidade entre acessar a memória alinhada ou desalinhada em relação à interface de memória externa. Dica: tome cuidado com os efeitos do cache.
Teste a diferença de velocidade entre acessar a memória em sequência ou com um determinado passo.
Como você pode medir o tamanho da cache em uma CPU?
Como você distribuiria os dados em vários canais de memória para obter largura de banda máxima? Como você o colocaria se tivesse muitos fios pequenos?
Um HDD de classe empresarial está girando a 10.000 rpm. Qual é o tempo absolutamente mínimo que um HDD precisa gastar no pior caso antes de poder ler os dados (você pode supor que os cabeçotes se movem quase instantaneamente)? Por que os HDDs de 2,5 “estão se tornando populares para servidores comerciais (em relação às unidades de 3,5” e 5,25 “)?
Suponha que um fabricante de HDD aumente a densidade de armazenamento de 1 Tbit por polegada quadrada para 5 Tbit por polegada quadrada. Quanta informação você pode armazenar em um anel em um HDD de 2,5 “? Há uma diferença entre as trilhas interna e externa?
As instâncias AWS P2 têm 16 GPUs K80 Kepler. Use
lspciem uma instância p2.16xlarge e p2.8xlarge para entender como as GPUs estão conectadas às CPUs. Dica: fique de olho nas pontes PCI PLX.Ir de tipos de dados de 8 para 16 bits aumenta a quantidade de silício em aproximadamente 4x. Por quê? Por que a NVIDIA pode ter adicionado operações INT4 a suas GPUs Turing?
Dados 6 links de alta velocidade entre GPUs (como para as GPUs Volta V100), como você conectaria 8 deles? Procure a conectividade usada nos servidores P3.16xlarge.
Quão mais rápido é ler para a frente na memória do que ler para trás? Este número difere entre diferentes computadores e fornecedores de CPU? Por quê? Escreva o código C e experimente-o.
Você pode medir o tamanho do cache do seu disco? O que é um HDD típico? Os SSDs precisam de um cache?
Meça a sobrecarga do pacote ao enviar mensagens pela Ethernet. Procure a diferença entre as conexões UDP e TCP / IP.
O acesso direto à memória permite que outros dispositivos além da CPU gravem (e leiam) diretamente na (da) memória. Por que isso é uma boa ideia?
Observe os números de desempenho da GPU Turing T4. Por que o desempenho “apenas” dobra quando você passa de FP16 para INT8 e INT4?
Qual é o menor tempo necessário para um pacote em uma viagem de ida e volta entre São Francisco e Amsterdã? Dica: você pode assumir que a distância é de 10.000 km.